|
CDISC
: Harmoniser les essais cliniques

Nicolas
de Saint Jorre
8 mars
2002
2/3
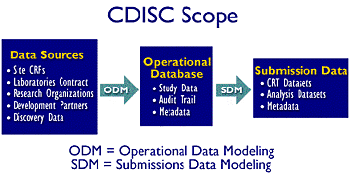
 L'organisation
du CDISC L'organisation
du CDISC
Operational
Data Model
Submission
Data Model (SDM)
Les
groupes de travail se partagent en deux grands groupes, en fonction
de la provenance de l'information :
L'
" Operational Data Modeling Team " (ODM) est en charge
de la mise en place des standards sous la forme de DTD (Document
Type Definition), une sorte de dictionnaire au format XML.
Il
doit permettre :
- L'acquisition
des données depuis un cahier d'observation (papier ou électronique),
depuis un laboratoire central, une CRO (Clinical Reseach Organisation),…
- L'échange
des données entre les différents intervenants du
secteurs de la recherche biomédicale,
- L'archivage
des données issues d'études cliniques.
Le
" Submission Data Standards Team " (SDM) est quant à
lui, en charge de la mise au point du modèle des Metadata
(données des données).
Operational Data Model
En
octobre 2001, le CDISC a distribué pour commentaires et pour
tests initiaux, le modèle de données opérationnel
" ODM (version 1.1) " sous la forme d'une DTD (XML DTD
for clinical data interchange ad archive).
Ce
modèle définit de façon très précise
trois types d'information en rapport avec un essai clinique :
- Métadata
d'un essai clinique : Study (définition d'un protocole
et des items),
- Données
administratives d'un essai clinique : AdminData (droits d'accès
et profils utilisateur),
- Données
cliniques d'un essai : ClinicalData (données cliniques
complètes avec notion d'audit).
Cette
DTD définit également les données de référence,
utilisées notamment pour les valeurs normales des examens
de laboratoire (ReferenceData).
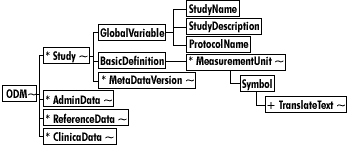
Figure 1 : Sections principales du modèle
Chaque
section inclus également des informations permettant de préciser
les éléments définissant le modèle.
Par exemple, la section " Study " est définit par
des variables globales (le nom de l'étude, une brève
description du projet, la référence du protocole,…),
des définitions basiques (comme les unités de mesure)
et par une définition sous forme de métadata de l'étude
(comme les visites prévues par le protocole, les formulaires
associés à chaque visite et les informations à
recueillir dans chaque formulaire).
Toutes ces informations sont organisées de façon hiérarchique
afin de prendre en compte le suivi des différentes révision
du modèle.
De la même façon, la section " Données
Cliniques " définit, pour un patient donné, l'ensemble
des informations cliniques attendues (StudyEventData, FormData,
ItemGroupData, ItemData). Cet
ensemble suit étroitement le modèle des métadatas.
Submission Data Model (SDM)
Le
Submission Data Model (SDM) est actuellement en version 2.0 depuis
Novembre 2001. Ce document est un guide pour l'organisation, le
contenu et la mise en page des dossiers de soumission pour la FDA
(Food and Drug Administration). Le CDISC prévoit d'ajouter
des nouveaux modèles pour d'autres types d'analyses mais
également pour des rapports de pharmacocinétique et
de pharmacodynamique, ainsi que des rapports d'efficacité
pour certaines aires thérapeutiques.
Le but premier du modèle Métadata (données
au sujet des données) est de fournir aux responsables réglementaires
une description claire de la structure, des attributs et du contenu
de chaque donnée, de chaque variable d'une base de donnée.
Ce modèle correspond bien évidemment au minimum d'information
à fournir à la FDA. Avec un tel document, les responsables
réglementaires peuvent reproduire la plupart des analyses,
des tables, des graphiques et des rapports avec un minimum ou pas
de transformation et sans aucune programmation particulière.
Le promoteur d'un essai clinique dispose ainsi de conventions pour
nommer un certain nombre d'éléments classiquement
utilisés en recherche biomédicale. Le groupe espère
ainsi bénéficier d'un dictionnaire de codage standard
ne compromettant pas les objectifs scientifiques de toute recherche.
En
partant du " NDA (New Drug Application) " de la FDA, le
groupe " Submission Data Standards " du CDISC a implémenté
un certain nombre d'amélioration en proposant les définitions
de fichier de données suivantes :
- Le nom
du fichier de données : nom sur 8 caractères
fourni par le promoteur pour nommer le fichier de données
(exemple : DEMO, AE ou ECG). La FDA recommandera des noms standards
pour les fichiers les plus communs,
- Description
:cette colonne contient une description plus détaillée
de l'information contenu dans le fichier de données (exemple
: " Demographics and Subject Characteristics DM),
- Localisation
: il est précisé ici le répertoire et le
nom du fichier de données permettant la localisation du
document (exemple : Demo.xpt),
- Structure
: Ce champ décrit la " forme " du fichier de
données. Par forme, il faut entendre représentation
de l'enregistrement par rapport à la notion de patient,
de visite, par événement (par exemple : un enregistrement
par patient et par visite). La structure d'un fichier de données
dépend du type de donnée, de l'indication et/ou
de la préférence du relecteur,
- Objectif
: cette colonne définie le but du fichier (soit "
CRT (Case Report Tabulations) ", soit " Analysis "),
- Index
: Cette colonne est utilisée pour identifier de façon
unique chaque enregistrement d'un fichier de données. La
plus part des fichiers présentent entre 3 et 5 clés
(exemple : USUBJID, VISIT).
Exemple de définition
des fichiers de données :
| Dataset |
Description |
Location |
Structure
[optional] |
Structure
[optional] |
Keys |
| DEMO |
Demographics
and Subject Characteristics DM |
Demo.xpt |
Demo.xpt |
CRT |
USUBJID |
| AE |
Adverse
Events AE |
Adv.xpt |
1 Rec per
subject per adverse event occurence |
CRT |
USUBJID,
AESEQ |
Le modèle
précise ensuite l'ensemble des variables de chaque fichier.
Certaines variables devraient se retrouver dans la plupart des dossiers.
|
 |
{bandeaudrit bas}
|


